
Few images on the Web receive alt-text descriptions that would make them accessible to blind and low vision (BLV) users. Image-based NLG systems have progressed to the point where they can begin to address this persistent societal problem, but these systems will not be fully successful unless we evaluate them on metrics that guide their development correctly. Here, we argue against current referenceless metrics -- those that don't rely on human-generated ground-truth descriptions -- on the grounds that they do not align with the needs of BLV users. The fundamental shortcoming of these metrics is that they cannot take context into account, whereas contextual information is highly valued by BLV users. To substantiate these claims, we present a study with BLV participants who rated descriptions along a variety of dimensions. An in-depth analysis reveals that the lack of context-awareness makes current referenceless metrics inadequate for advancing image accessibility, requiring a rethinking of referenceless evaluation metrics for image-based NLG systems.
In the pursuit of ever more powerful image description systems, we need evaluation metrics that provide a clear window into model capabilities. At present, we are seeing a rise in referenceless (or reference-free) metrics (Hessel et al. 2021; Lee, Scialom, et al. 2021; Lee, Yoon, et al. 2021; Feinglass and Yang 2021), building on prior work in domains such as machine translation (Lo 2019; Zhao et al. 2020) and summarization (Louis and Nenkova 2013; Peyrard and Gurevych 2018). These metrics seek to estimate the quality of a text corresponding to an image without requiring ground truth labels, crowd worker judgments, or reference descriptions. In this work, we investigate the current value of such metrics for assessing the usefulness of image descriptions for blind and low vision (BLV) users.
Images have become central in all areas of digital communication, from scientific publishing to social media memes (Hackett, Parmanto, and Zeng 2003; Bigham et al. 2006; Buzzi, Buzzi, and Leporini 2011; Morris et al. 2016; Voykinska et al. 2016; Gleason et al. 2019). While images can be made nonvisually accessible with image descriptions, these are rare, with coverage as low as 0.1% on English-language Twitter (Gleason et al. 2020). In light of this challenge, there are numerous efforts underway to investigate what makes descriptions useful and develop models to artificially generate such descriptions at scale.
Referenceless metrics offer the promise of quick and efficient evaluation of models that generate image descriptions, and they are even suggested to be more reliable than existing reference-based metrics (Kasai, Sakaguchi, Dunagan, et al. 2021; Kasai, Sakaguchi, Bras, et al. 2021). The question then arises of whether referenceless metrics can provide suitable guidance for meeting accessibility needs.
There are two main categories of referenceless metrics. Imaged-based metrics assess a description’s quality relative to its associated image. The most prominent example is CLIPScore (Hessel et al. 2021), a metric based on CLIP – a multi-modal model trained on a large image–text dataset (Radford et al. 2021). CLIPScore provides a compatibility score for image–text pairs, leveraging the fact that CLIP was trained contrastively with positive and negative examples (Hessel et al. 2021; Lee, Yoon, et al. 2021). In contrast, text-based metrics rely entirely on intrinsic properties of the description text. For instance, SPURTS rates a description based on its linguistic style by leveraging the information flow in DistilRoBERTa, a large language model (Feinglass and Yang 2021).
Do referenceless metrics, of either type, align with what BLV users value in image descriptions for accessibility? Studies with BLV users highlight that the context in which an image appears is important. For example, while the clothes a person is wearing are highly relevant when browsing through shopping websites, the identity of the person becomes important when reading the news (Stangl et al. 2021; Muehlbradt and Kane 2022; Stangl, Morris, and Gurari 2020). Not only the domain but even the immediate context matters for selecting what is relevant. Consider the image in Figure 1, showing a park with a gazebo in the center and a sculpture on a pedestal in the foreground. This image could appear for instance in the Wikipedia article on sculptures or gazebos. However, an image description written for the image’s occurrence in the article of gazebos (“A freestanding, open, hexagonal gazebo with a dome-like roof in an idyllic park area.”) becomes unhelpful for the occurrence of the image in the article on sculptures. Thus, context could play a central role in the assessment of description quality.
In this work, we report on studies with sighted and BLV participants that seek to provide rich, multidimensional information about what people value in accessibility image descriptions. Our central manipulation involves systematically varying the Wikipedia articles the images are presented as appearing in, and studying the effects this has on participants’ judgments. For both sighted and BLV participants, we observe strong and consistent effects of context. However, by their very design, current referenceless metrics can’t capture these effects, since they treat description evaluation as a context-less problem. This shortcoming goes undetected on most existing datasets and previously conducted human evaluations, which presume that image descriptions are context-independent.
Image accessibility is a prominent and socially important goal that image-based NLG systems are striving to reach (Gurari et al. 2020). Our results suggest that current referenceless metrics may not be reliable guides in these efforts.
Screen readers provide auditory and braille access to Web content. To make images accessible in this way, screen readers use image descriptions embedded in HTML alt tags. However, such descriptions are rare. While frequently visited websites are estimated to have about 72% coverage (Guinness, Cutrell, and Morris 2018), this drops to less than 6% on English-language Wikipedia (Kreiss, Goodman, and Potts 2022) and to 0.1% on English-language Twitter (Gleason et al. 2019). This has severe implications especially for BLV users who have to rely on such descriptions to engage socially (Morris et al. 2016; MacLeod et al. 2017; Buzzi, Buzzi, and Leporini 2011; Voykinska et al. 2016) and stay informed (Gleason et al. 2019; Morris et al. 2016).
Moreover, these coverage estimates are based on any description being available, without regard for whether the descriptions are useful. Precisely what constitutes a useful description is still an underexplored question. A central finding from work with BLV users is that one-size-fits-all image descriptions don’t address image accessibility needs (Stangl et al. 2021; Muehlbradt and Kane 2022; Stangl, Morris, and Gurari 2020). Stangl et al. (2021) specifically tested the importance of the scenario – the source of the image and the informational goal of the user – by placing each image within different source domains (e.g., news or shopping website) which were associated with specific goals (e.g., learning or browsing for a gift). They find that BLV users have certain description preferences that are stable across scenarios (e.g., people’s identity and facial expressions, or the type of location depicted), whereas others are scenario-dependent (e.g., hair color). We extend this previous work by keeping the scenario stable but varying the immediate context the image is embedded in.
Current referenceless metrics take the one-size-fits-all approach. We explicitly test whether this is sufficient to capture the ratings provided by BLV users when they have access to the broader context.
There are two evaluation strategies for automatically assessing the quality of a model’s generated text from images: reference-based and referenceless (or reference-free) metrics.
Reference-based metrics rely on ground-truth texts associated with each image that were created by human annotators. The candidate text generated by the model is then compared with those ground-truth references, returning a similarity score. A wide variety of scoring techniques have been explored. Examples are BLEU (Papineni et al. 2002), CIDEr (Vedantam, Lawrence Zitnick, and Parikh 2015), SPICE (Anderson et al. 2016), ROUGE (Lin 2004), and BERTscore (Zhang et al. 2019). The more references are provided, the more reliable the scores, which requires datasets with multiple high-quality annotations for each image. Such datasets are expensive and difficult to obtain.
As discussed above, referenceless metrics dispense with the need for ground-truth reference texts. Instead, text quality is assessed based either on how the text relates to the image content (Hessel et al. 2021; Lee, Yoon, et al. 2021; Lee, Scialom, et al. 2021) or on text quality alone (Feinglass and Yang 2021). As a result, these metrics can in principle be used anywhere without the need for an expensive annotation effort. How the score is computed varies between metrics. CLIPScore (Hessel et al. 2021) and UMIC (Lee, Yoon, et al. 2021) pose a classification problem where models are trained contrastively on compatible and incompatible image–text pairs. A higher score for a given image and text as input then corresponds to a high compatibility between them. QACE provides a high score if descriptions and images provide similar answers to the same questions (Lee, Scialom, et al. 2021). SPURTS is a referenceless metric which judges text quality solely based on text-internal properties that can be conceptualized as maximizing unexpected content (Feinglass and Yang 2021). SPURTS was originally proposed as part of the metric SMURF which additionally contains a reference-based component, specifically designed to capture the semantics of the description. However, Feinglass and Yang (2021) find that SPURTS alone already seems to approximate human judgments well, which makes it a relevant referenceless metric to consider. While varying in their approach, all current referenceless metrics share that they treat image-based text generation as a context-independent problem.
Reference-based metrics have the potential to reflect context-dependence, assuming the reference texts are created in ways that engage with the context the image appears in. Referenceless methods are much more limited in this regard: if a single image–description pair should receive different scores in different contexts, but the metric operates only on image–description pairs, then the metric will be intrinsically unable to provide the desired scores.
Efforts to obtain and evaluate image descriptions through crowdsourcing are mainly conducted out-of-context: images that might have originally been part of a tweet or news article are presented in isolation to obtain a description or evaluation thereof. Following recent insights on the importance of the domains an image appeared in (Stangl et al. 2021; Muehlbradt and Kane 2022; Stangl, Morris, and Gurari 2020), we seek to understand the role of context in shaping how people evaluate descriptions. Figure 2 provides an overview of the two main phases. Firstly, we obtained contextual descriptions by explicitly varying the context each image could occur in (Figure 2A). We then explored how context affects sighted and BLV users’ assessments of descriptions along a number of dimensions (Figure 2B). Finally, in Section 4, we compare these contextual evaluations with the results from the referenceless metrics CLIPScore (Hessel et al. 2021) and SPURTS (Feinglass and Yang 2021).
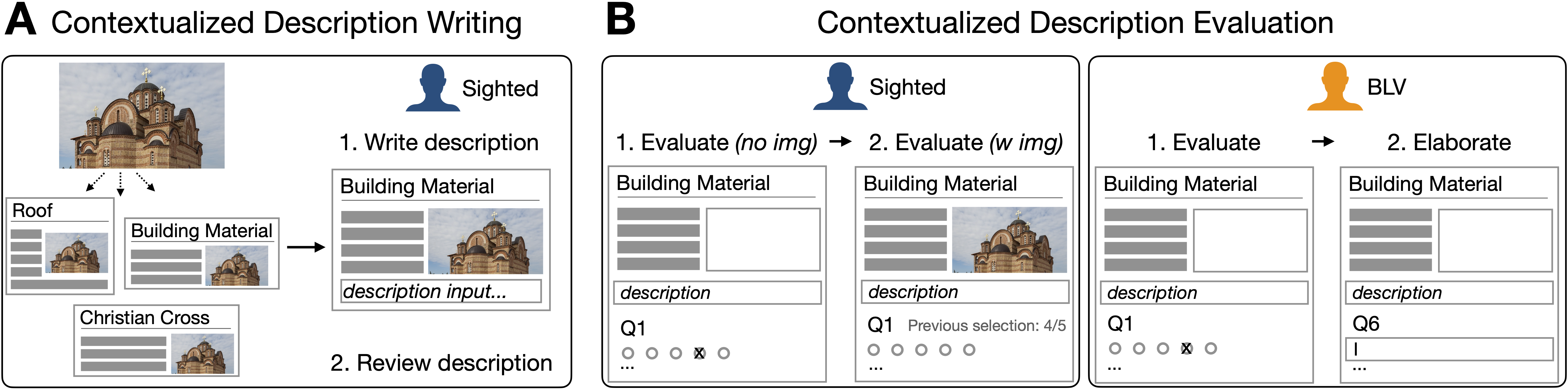
To investigate the effect of context on image descriptions, we designed a dataset where each image was paired with three distinct contexts, here Wikipedia articles. For instance, an image of a church was paired with the first paragraphs of the Wikipedia articles on Building material, Roof, and Christian cross. Similarly, each article appeared with three distinct images. The images were made publicly available through Wikimedia Commons. Overall, we obtained 54 unique image–context pairs, consisting of 18 unique images and 17 unique articles. The dataset, experiments used for data collection, and analyses are made available.2
To obtain image descriptions, we recruited 74 participants on Amazon’s Mechanical Turk for the task of providing image descriptions that could make the images accessible to users who can’t see them.
Each participant went through a brief introduction explaining the challenge and purpose of image descriptions and was then shown six distinct articles, each of them containing a different image they were asked to describe. To enable participants to judge their descriptions, the description then replaced the image and participants could choose to edit their response before continuing. The task did not contain any guidance on which information should or should not be included in the description. Consequently, any context-dependence is simply induced by presenting the images within contexts (Wikipedia articles) instead of in isolation.
We excluded six participants who indicated confusion about the task in the post-questionnaire and one participant for whom the experiment didn’t display properly. Overall, each image–article pair received on average five descriptions.
After exclusions, we obtained 272 descriptions that varied in length between 13 and 541 characters, with an average of 24.9 words. With the following human subject evaluation experiment, we evaluate to what extent the description content was affected by the image context.
After obtaining contextual image descriptions, we designed a description evaluation study which we conducted with BLV as well as sighted participants. Both groups can provide important insights. We consider the ratings of BLV participants as the primary window into accessibility needs. However, sighted participant judgments can complement these results, in particular by helping us determine whether a description is true for an image. Furthermore, the sighted participants’ intuitions about what makes a good description are potentially informative since sighted users are usually the ones providing image descriptions.
Sighted as well as BLV participants rated each image description as it occurred within the respective Wikipedia article. To get a better understanding of the kinds of content that might affect description quality, each description was evaluated according to five dimensions:
Overall: How good the description seemed overall.
Imaginability: How well the description helped the participant imagine the image.
Relevance: How well the description captured relevant information.
Irrelevance: How much extra (irrelevant) information it added.
Fit: How well the image seemed to fit within the article.
The questions Imaginability and Relevance are designed to capture two central aspects of description content. While Imaginability has no direct contextual component, Relevance and Irrelevance specifically ask about the contextually determined aspects of the description. These dimensions give us insights into the importance of context in the Overall description quality ratings.
Responses were provided on 5-point Likert scales. In addition to 17 critical trials each participant completed, we further included two trials with descriptions carefully constructed to exhibit for instance low vs. high context sensitivity. These trials allowed us to ensure that the questions and scales were interpreted as intended by the participants. Overall, each participant completed 19 trials, where each trial consisted of a different article and image. Trial order and question order were randomized between participants to avoid potential ordering biases.
To ensure high data quality, sighted participants were asked a reading comprehension question before starting the experiment which also familiarized them with the overall topic of image accessibility. If they passed, they could choose to enter the main study, otherwise they exited the study and were only compensated for completing the comprehension task.
In each trial, participants first saw the Wikipedia article, followed by an image description. This no image condition can be conceptualized as providing sighted participants with the same information a BLV user would be able to access. They then responded to the five questions and were asked to indicate if the description contained false statements or discriminatory language. After submitting the response, the image was revealed and participants responded again to four of the five questions. The Imaginability question was omitted since it isn’t clearly interpretable once the image is visible. Their previous rating for each question was made available to them so that they could reason about whether they wanted to keep or change their response.
79 participants were recruited over Amazon’s Mechanical Turk, 68 of whom continued past the reading comprehension question. We excluded eight participants since they spent less than 19 minutes on the task, and one participant whose logged data was incomplete. This resulted in 59 submissions for further analysis.
The 68 most-rated descriptions across the 17 Wikipedia articles and 18 images were then selected to be further evaluated by BLV participants.
To provide BLV participants with the same information as sighted participants, they similarly started with the reading comprehension question before continuing to the main trials. After reading the Wikipedia article and the image descriptions, participants first responded to the five evaluation dimensions. Afterwards, they provided answers to five open-ended questions about the description content. The main focus of the analysis presented here is on the Likert scale responses, but the open-ended explanations allow more detailed insights into description preferences. Each description was rated by exactly four participants.
16 participants were recruited via targeted email lists for BLV users, and participants were unknowing about the purpose of the study. Participants self-described their level of vision as totally blind (7), nearly blind (3), light perception only (5), and low vision (1). 15 participants reported relying on screen readers (almost) always when browsing the Web, and one reported using them often.
We enrolled fewer blind participants than sighted participants, as they are a low-incidence population, requiring targeted and time-consuming recruitment. For example, crowd platforms that enable large sample recruitment are inaccessible to blind crowd workers (Vashistha, Sethi, and Anderson 2018).
The following analyses are based on the 68 descriptions, comprising 18 images and 17 Wikipedia articles. Each description is evaluated according to multiple dimensions by sighted as well as BLV participants for how well the description serves an accessibility goal.
Figure 3 shows the correlation of BLV and sighted participant ratings across questions. We find that the judgments of the two groups are significantly correlated for all questions. The correlation is encouraging since it shows an alignment between the BLV participants’ reported preferences and the sighted participants’ intuitions. Whether sighted participants could see the image when responding didn’t make a qualitative difference. The results further show that the dataset provides very poor to very good descriptions, covering the whole range of possible responses. This range is important for insights into whether a proposed evaluation metric can detect what makes a description useful.
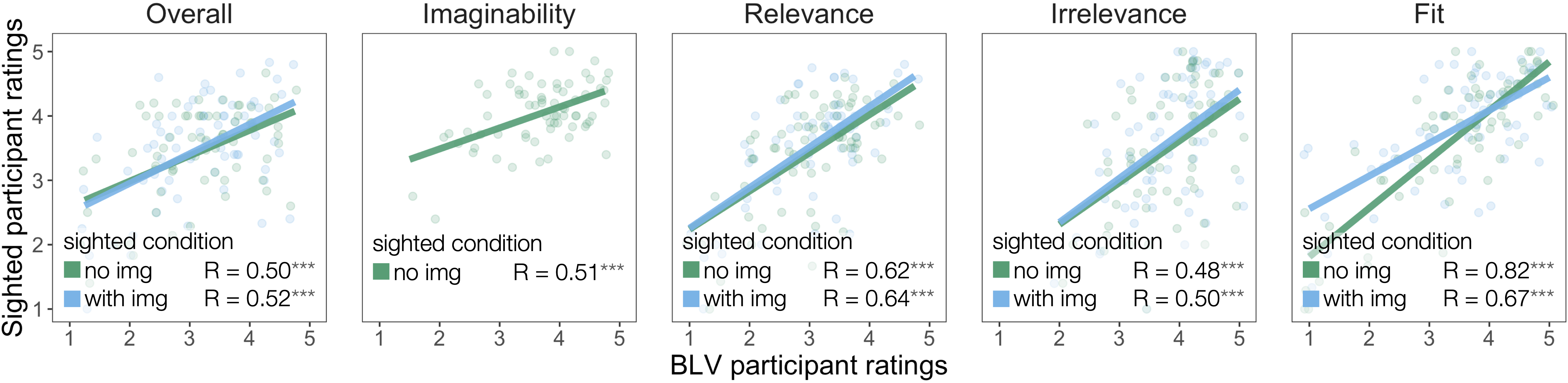
We conducted a mixed effects linear regression analysis of the BLV participant judgments to investigate which responses are significant predictors of the overall ratings. We used normalized and centered fixed effects of the three content questions (Imaginability, Relevance and Irrelevance), and random by-participant and by-description intercepts. If context doesn’t affect the quality of a description, Imaginability should be a sufficient predictor of the overall ratings. However, in addition to an effect of Imaginability (β = .42, SE = .06, p < .001), we find a significant effect of Relevance as well (β = .44, SE = .05, p < .001), suggesting that context plays an essential role in guiding what makes a description useful. This finding replicates with the sighted participant judgments.
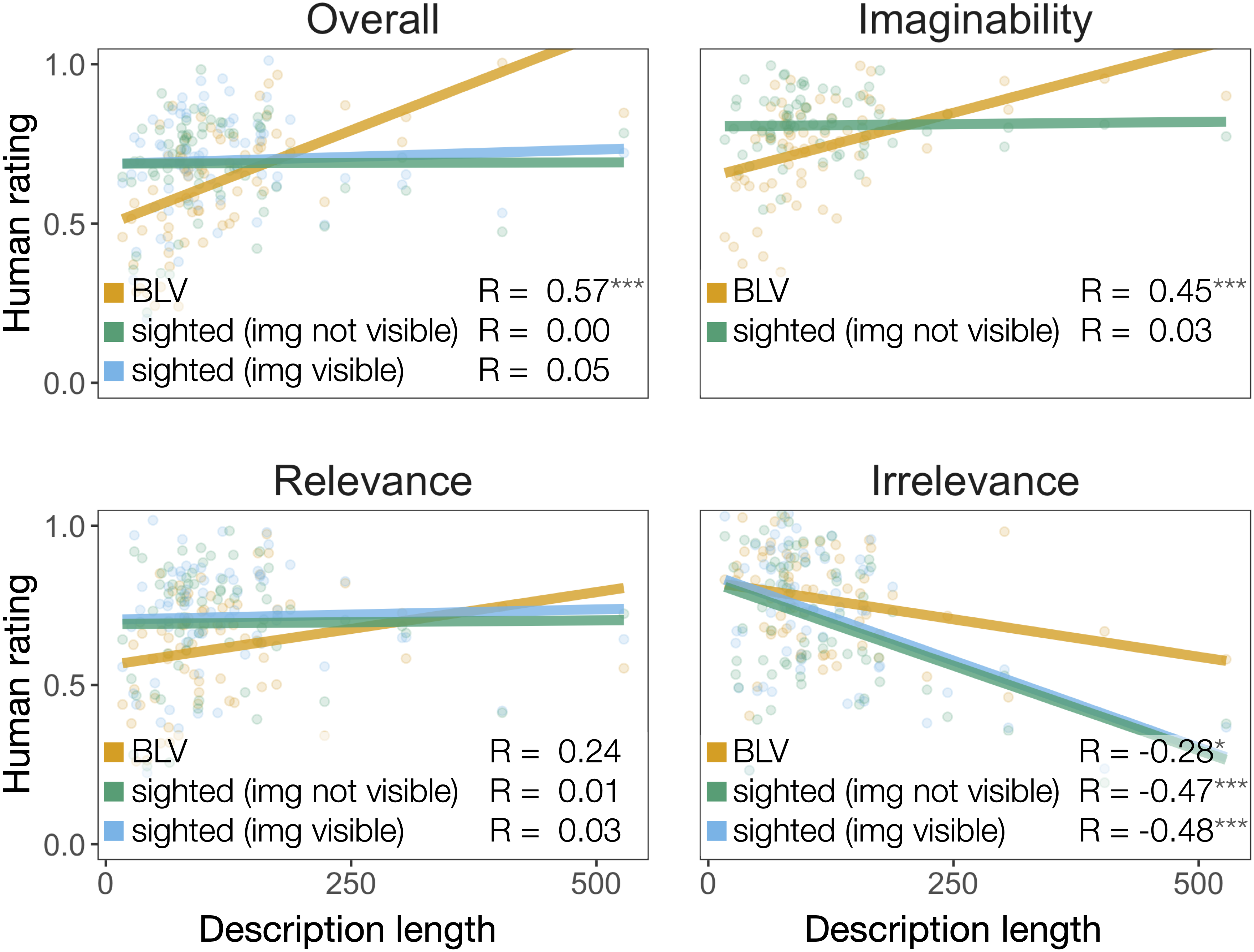
A case where BLV and sighted participant ratings diverge is in the effect of description length (Figure 4). While longer descriptions tend to be judged overall more highly by BLV participants, there is no such correlation for sighted participants. This finding contrasts with popular image description guidelines, which generally advocate for shorter descriptions.3 The lack of correlation between sighted participant ratings and description length might be linked to this potential misconception.
Referenceless metrics have been shown to correlate well with how sighted participants judge description quality when descriptions are written and presented out-of-context (Hessel et al. 2021; Feinglass and Yang 2021; Lee, Yoon, et al. 2021; Kasai, Sakaguchi, Dunagan, et al. 2021). While image accessibility is one of the main goals referenceless metrics are intended to facilitate (Kasai, Sakaguchi, Bras, et al. 2021; Hessel et al. 2021; Kasai, Sakaguchi, Dunagan, et al. 2021), it remains unclear whether they can approximate the usefulness of a description for BLV users. Inspired by recent insights into what makes a description useful, we argue that the inherently decontextualized nature of current referenceless metrics makes them inadequate as a measure of image accessibility. We focus on two referenceless metrics to support these claims: CLIPScore (Hessel et al. 2021) and SPURTS (Feinglass and Yang 2021).
CLIPScore is currently the most prominent referenceless metric, and it seems likely to inspire additional similar metrics, given the rising number of successful multimodal models trained under contrastive learning objectives. While CLIPScore has been tested on a variety of datasets and compared to crowd worker judgments, it has so far been disconnected from insights into what makes descriptions useful for accessibility.
CLIPScore uses the similarity of CLIP’s image and description embeddings as the predictor for description quality, as formulated in the following equation. Denoting \(\frac{x}{|x|}\) (i.e., x divided by its norm) as \(\overline{x}\) (i.e., x-bar), we can express CLIPScore as $$\label{eq:clipscore} \text{max}\left({\overline{\textnormal{image}}} \cdot {\overline{\textnormal{description}}}, 0\right),$$ i.e., the score corresponds to the dot product of the image-bar and description-bar representations if above 0, otherwise 0.
SPURTS is different from CLIPScore since it only considers the description itself, without taking image information into account. The main goal of SPURTS is to detect fluency and style, and it can be written as $$\label{eq:spurts} \textnormal{median}_{\textnormal{layer}} \textnormal{max}_{\textnormal{head}} \ I_{\textnormal{flow}}(y_{w/o}, \theta),$$ where \(I_{\textnormal{flow}}\), which Feinglass and Yang (2021) refer to as information flow, is normalized mutual information as defined in Witten et al. (2005). For an input text without stop words, yw/o, and a transformer with parameters θ, SPURTS computes the information flow for each transformer head at each layer, and then returns the layer-wise median of the head-wise maxima.
We turn now to assessing the extent to which CLIPScore and SPURTS approximate the ratings of the BLV and sighted users from our studies. Our central conclusion is that the context-independence of these metrics makes them inadequate for approximating description quality.
We first inspect the extent to which current referenceless metrics can capture whether a description is true for an image. SPURTS provides scores independent of the image and therefore inherently can’t capture any notion of truthfulness. In contrast, CLIPScore is trained to distinguish between fitting and non-fitting image–text pairs, returning a compatibility score. We test whether this generalizes to our experimental data by providing CLIPScore with the true descriptions written for each image and a shuffled variant where images and descriptions were randomly paired. As Figure 4A demonstrates, CLIPScore rates the ordered pairs significantly higher compared to the shuffled counterparts (β = 2.02, SE = .14, p < .001),4 suggesting that it captures image–text compatibility.
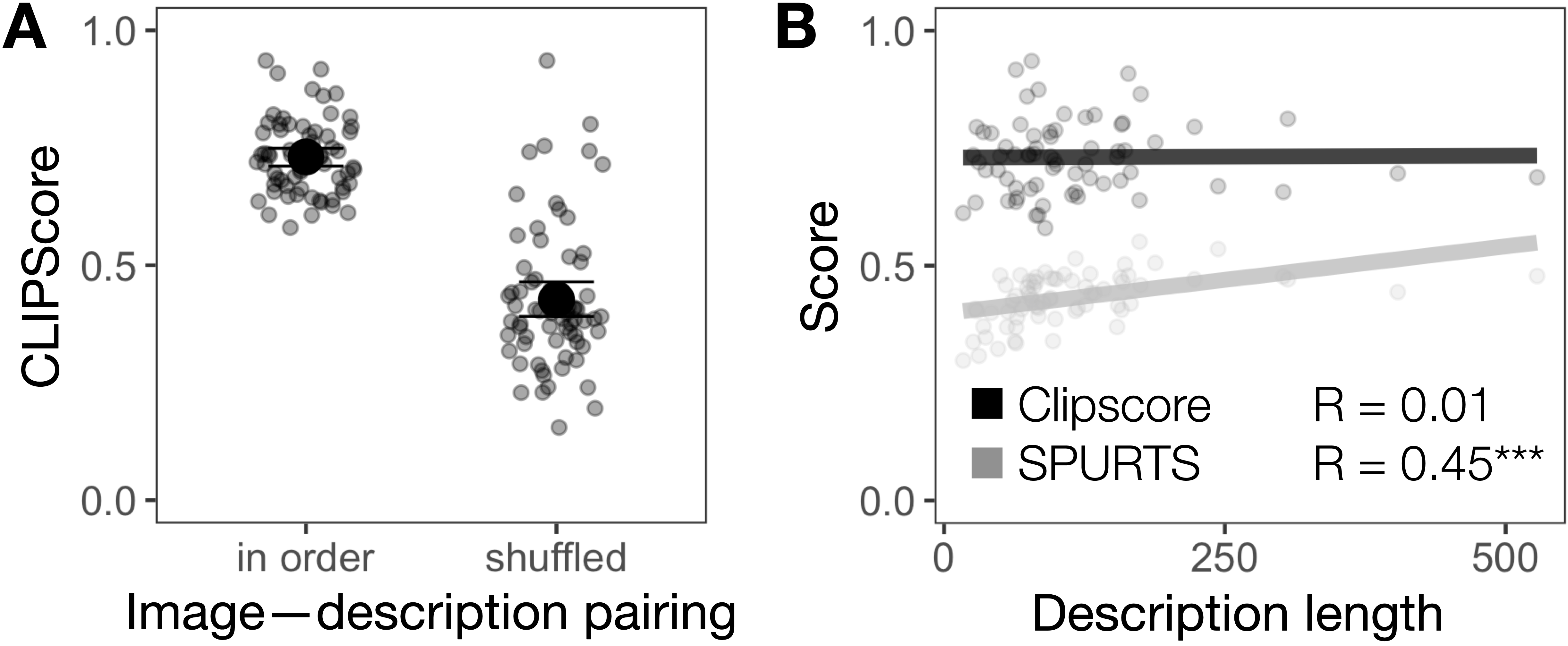
Since the length of the description can already account for some of the variance of the BLV ratings, we further investigate whether description length is a general predictor for CLIPScore and SPURTS (see Figure 4B). For CLIPScore, description length doesn’t correlate with predicted quality of the description, which is likely a consequence of the contrastive learning objective, which only optimizes for compatibility but not quality. SPURTS scores, in contrast, significantly correlate with description length, which is aligned with the BLV ratings.
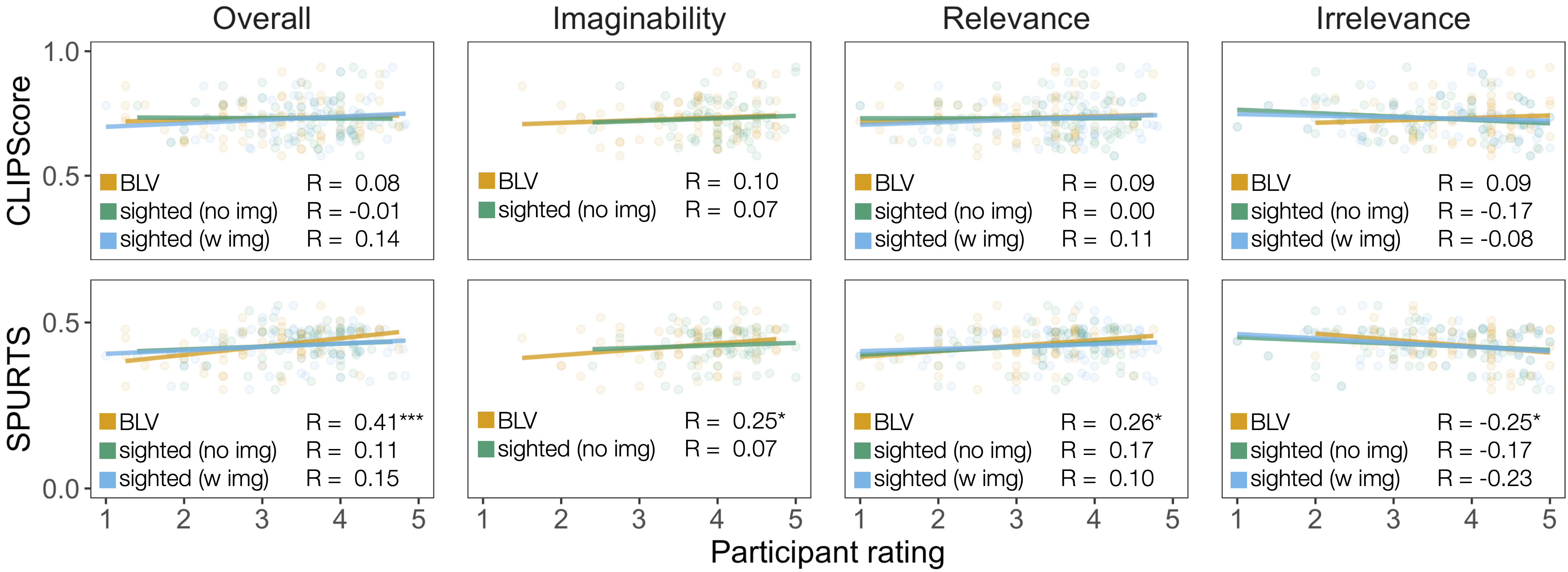
Crucially, the descriptions were written and evaluated within contexts, i.e., their respective Wikipedia article, and previous work suggests that the availability of context should affect what constitutes a good and useful description. Since current referenceless metrics can’t integrate context, we expect that they shouldn’t be able to capture the variation in the human description evaluations, and this is indeed what we find.
To investigate this hypothesis, we correlated sighted and BLV description evaluations with the CLIPScore and SPURTS ratings. As shown in Figure 5, CLIPScore fails to capture any variation observed in the human judgments across questions. This suggests that, while CLIPScore can add a perspective on the compatibility of a text for an image, it can’t get beyond that as an indication of how useful a description is if it’s true for the image.
Like CLIPScore, SPURTS scores don’t correlate with the sighted participant judgments (see Figure 5, bottom). However, specifically with respect to the overall rating, SPURTS scores show a significant correlation with the BLV participant ratings. While this seems encouraging, further analysis revealed that this correlation is primarily driven by the fact that both BLV and SPURTS ratings correlate with description length. The explained variance of the BLV ratings from description length alone is 0.152 and SPURTS score alone explains 0.08 of the variance. In conjunction, however, they only explain 0.166 of the variance, which means that most of the predictability of SPURTS is due to the length correlation. This is further supported by a mixed effects linear regression analysis in which we fail to find a significant effect of SPURTS (β = .80, SE = .44, p > .05) once we include length as a predictor (β = .64, SE = .15, p < .001).5
A further indication that SPURTS isn’t capturing essential variance in BLV judgments is apparent from the negative correlation in the Irrelevance question (R = − 0.25). This suggests that SPURTS scores tend to be higher for descriptions that are judged to contain too much irrelevant information and low when participants assess the level of information to be appropriate. In the BLV responses, Irrelevance is positively correlated with the Overall ratings (R = 0.33), posing a clear qualitative mismatch to SPURTS. Since what is considered extra information is dependent on the context, this is a concrete case where the metric’s lack of context integration results in undesired behavior.
Finally, SPURTS’ complete lack of correlation with sighted participant judgments further suggests that SPURTS is insufficient for picking up the semantic components of the descriptions. This aligns with the original conception of the metric, where a reference-based metric (SPARCS) is used to estimate semantic quality.
Overall, our results highlight that SPURTS captures the BLV participants’ preferences for longer descriptions but falls short in capturing additional semantic preferences, and is inherently inadequate for judging the truthfulness of a description more generally. CLIPScore can’t capture any of the variation in BLV or sighted participant ratings, uncovering clear limitations.
In the previous experiments, we established that the referenceless metrics CLIPScore and SPURTS can’t get traction on what makes a good description when the images and descriptions are contextualized. Other referenceless metrics such as UMIC (Lee, Yoon, et al. 2021) and QACE (Lee, Scialom, et al. 2021) face the same fundamental issue as CLIPScore and SPURTS due to their contextless nature. Like CLIPScore, UMIC is based on an image–text model (UNITER; Chen et al. (2020)) trained under a contrastive learning objective. Similarly, it produces an image–text compatibility score solely by receiving a decontextualized image and text as input. QACE uses the candidate description to derive potential questions that should be answerable based on the image. The evaluation is therefore whether the description mentions aspects that are true of the image and not about which aspects of the image are relevant to describe. This again only provides insights into image–text compatibility but not contextual relevance.6
In summary, the current context-independence of all existing referenceless metrics is a major limitation for their usefulness. This is a challenge that needs to be addressed to make these metrics a useful tool for advancing image-based NLG systems.
So far, we have argued that CLIPScore and other referenceless metrics aren’t a useful approximation for BLV (and sighted) user judgments of high-quality descriptions, primarily due to their contextless nature. Using the example of CLIPScore, we will now explore where future work on referenceless metrics in image-based NLG can progress and also discuss some underlying limitations.
Can referenceless metrics like CLIPScore be made context sensitive? To begin exploring this question, as a proof of concept, we amend the CLIPScore equation as follows: $$\begin{gathered} \label{eq:clipwcontext} \overline{\textnormal{description}} \cdot \textnormal{context} \ + \\ \textnormal{description} \cdot \left(\overline{\textnormal{image}} - \overline{\textnormal{context}}\right)\end{gathered}$$ Here, quality is a function of (a) the description’s similarity to the context (first addend, i.e., the dot product of description-bar and context representations) and (b) whether the description captures the information that the image adds to the context (second addend, i.e., the dot product of the description representation and the difference between image-bar and context-bar representations). These two addends can be seen as capturing aspects of (ir)relevance and imaginability, respectively, though we anticipate many alternative ways to quantify these dimensions.
Table 1 reports correlations between this augmented version of CLIPScore and our sighted and BLV participant judgments. We find it encouraging that even this simple approach to incorporating context boosts correlations with human ratings for all the questions in our experiment. For the Irrelevance question, it even clearly captures the positive correlation with BLV ratings, which is negative for both CLIPScore and SPURTS, indicating a promising shift. We consider this an encouraging signal that large pretrained models such as CLIP might still constitute a resource for developing future referenceless metrics.
| Overall | Imaginability | Relevance | Irrelevance | ||
|---|---|---|---|---|---|
| CLIPScore: | BLV | 0.075 | 0.104 | 0.086 | 0.090 |
| With Context: | BLV | 0.201 | 0.182 | 0.202 | 0.142 |
| CLIPScore: | sighted, no img | −0.013 | 0.064 | 0.000 | −0.166 |
| With Context: | sighted, no img | 0.238 | 0.315 | 0.190 | −0.019 |
| CLIPScore: | sighted, w img | 0.139 | 0.106 | −0.079 | |
| With Context: | sighted, w img | 0.331 | 0.240 | 0.052 |
However, despite these promising signs, there are also reasons to believe that CLIP-based metrics have other restrictive limitations. Due to CLIP’s training, images are cropped at the center region and texts need to be truncated at 77 tokens (Radford et al. 2021). Specifically for the purpose of accessibility, the information this removes can be crucial for determining whether a description is useful or not. For instance, our experiments show that the length of a description is an important indicator for description quality – information lost in CLIP-based metrics. Moreover, this disproportionately affects the ability to encode the context paragraphs, which are often longer than a typical description. These decisions are therefore likely reflected in any resulting metric and should therefore be reconsidered when devising a new metric.
While we have specifically focused on the usefulness of referenceless metrics for image accessibility, this isn’t the only potential purpose an image-based text might address. Kreiss, Goodman, and Potts (2022) distinguish descriptions, i.e., image-based texts that are written to replace the image, and captions, i.e., texts that are intended to appear alongside images, such as tweets or newspaper captions. This suggests that the same text can be very useful for contextualizing an image but fail at providing image accessibility, and vice versa. To investigate this distinction, they asked participants to rate alt descriptions as well as image captions from Wikipedia according to (1) how much the text helped them imagine the image, and (2) how much they learned from the text that they couldn’t have learned from the image. Descriptions were rated more useful for imagining the image, whereas captions were rated more useful for learning additional information. Captions used for contextualizing an image might therefore be another potential use domain for a referenceless metric such as CLIPScore.
To see whether CLIPScore might be a promising resource for evaluating captions, we obtained CLIPScore ratings for the descriptions and captions in Kreiss, Goodman, and Potts (2022). CLIPScore ratings correlate with the reconstruction as opposed to the contextualization goal (see Figure 6), suggesting that CLIPScore is inherently less appropriate to be used for assessing caption datasets. This aligns with the original observation in Hessel et al. (2021) that CLIPScore performs less well on the news caption dataset GoodNews (Biten et al. 2019) compared to MSCOCO (Hessel et al. 2021), a contextless description dataset.
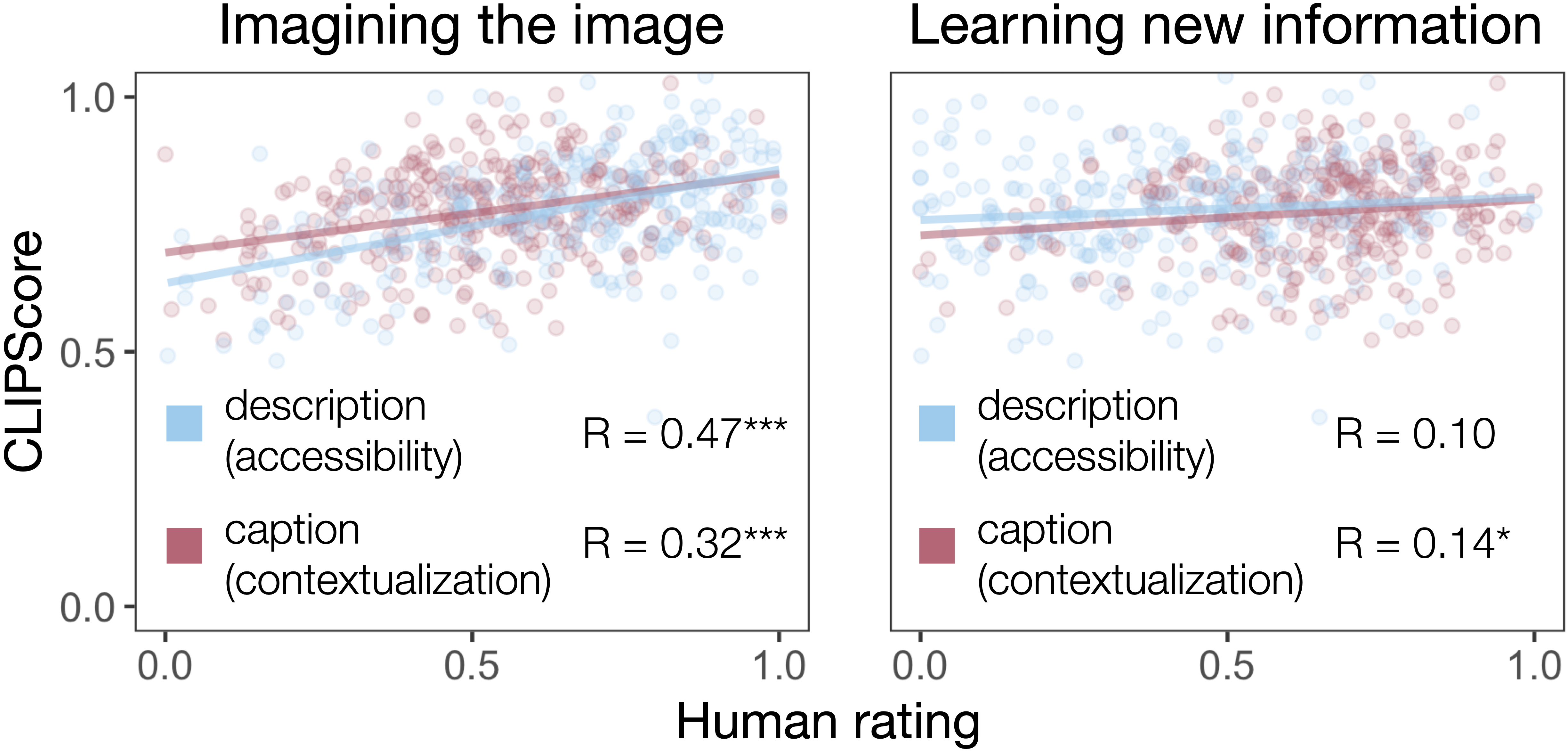
Taken together, this suggests that the “one-size-fits-all” approach to referenceless image-based text evaluation is not sufficient for adequately assessing text quality for the contextualization or the accessibility domain.
The context an image appears in shapes the way high-quality accessibility descriptions are written. In this work, we reported on experiments in which we explicitly varied the contexts images were presented in and investigated the effects of this contextual evaluation on participant ratings. These experiments reveal strong contextual effects for sighted and BLV participants. We showed that this poses a serious obstacle for current referenceless metrics.
Our results have wide implications for research on automatic description generation. The central result is that context plays an important role in what makes a description useful. Not realizing that leads to datasets and evaluation methods that don’t actually optimize for accessibility. Thus, we need to situate datasets and models within contexts, and evaluation methods need to be sensitive to context. In light of the benefits of referenceless metrics, we feel it is imperative to explore ways for them to incorporate context and to assess the resulting scores against judgments from BLV users.
This work is supported in part by a grant from Google through the Stanford Institute for Human-Centered AI and by the NSF under project REU-1950223. We thank our experiment participants for their invaluable input.
Corresponding author: ekreiss@stanford.edu↩︎
https://github.com/elisakreiss/contextual-description-evaluation↩︎
Result from a linear effects analyses where the shuffled condition is coded as 0, and the ordered condition as 1.↩︎
We assume random intercepts by participant and description, and we rescaled description length to fall in the range between 0 and 1.↩︎
Unfortunately, we are unable to provide quantitative results for these referenceless metrics since the authors haven’t provided the code necessary (QACE), or the code relies on image features that can’t be created for novel datasets with currently available hardware (UMIC, QACE).↩︎